
由于自身职业的原因,会经常接触到各行各业的资讯和商业计划书, 但直觉告诉我,现在暂时还没到投资国产AI的时候。至于具体原因,我认为是不论在硬件层面的GPU,还是系统层面的大模型,国产AI还是跟国外存在着一定差距,而这种差距在短期内难以追赶。所以我在整个23年是处于观望状态去对待国产AI的投资。
CUDA生态的坎
24年年初,无意之间收到了壁仞科技的商业计划书,但公司管理层正值处于大变动的时候,公司的联合创始人相继先后离职。先撇开公司内部问题不说, 我认为目前国产GPU、AI芯片公司还有一道短时间内难以翻越的大山,英伟达的CUDA生态平台。现有几乎所有从事AI工作的开发者都是CUDA的用户,而几乎所有的开源大模型都是基于英伟达的CUDA来实现并行加速。 如果要实现平替,只能
- 通过指令翻译的方式兼容CUDA;但这会导致性能上的损耗和对CUDA兼容更新不及时的问题。
- 让开发者将现有代码迁移至新的GPU平台上;但面对现阶段开源大模型及应用进入井喷期,其迁移成本非常昂贵。
不论是那种方式,对于现有开发者来说并不是最优选择。 这就导致了一个恶性的循环,形成了国产AI难发展、国产AI发展难的局面。
虽然像壁仞科技这种实力雄厚的公司前两年就实现了用于平替CUDA的壁仞SUPA平台的开发,但其核心还是离不开“兼容”和“”迁移“两大原则。
关于”翻译层“,这里有段小插曲。
在3月初的时候,英伟达突然在其CUDA的最终用户许可协议(EULA)中增加了”禁止在其他硬件平台上使用翻译层运行基于CUDA的软件“的警告。我综合了现有公开信息来看,虽然这条款实则上是警告AMD和英特尔支持的ZLUDA翻译层平台, 但由于众多国产GPU制造商都在自家的平台上使用了”翻译层“,因此,这消息当时引起了不少国产GPU创业公司出来发澄清公告。1
遥遥领先和鸿沟
五一节前,由于另外一个投资项目去了一趟深圳拜访了一个同行投资机构。其中聊到了关于目前国产GPU发展和与英伟达的差距时,在场的人员似乎都有一种有共识:华为的海思是中国最强,海思单个GPU 很强,但一旦要实现多个GPU互连时就不行了。 这该怎么理解呢?
实际上华为的海思和英伟达在GPU互连时,总算力的差距主要在于连接的带宽上。
- 英伟达的NVLink采用全网状拓扑,互连时GPU-to-GPU(双向)最大带宽可达到400GB/s;2
- 华为的HCCS采用对等拓扑,所以互连时 GPU-to-GPU (双向)最大带宽是56GB/s;3
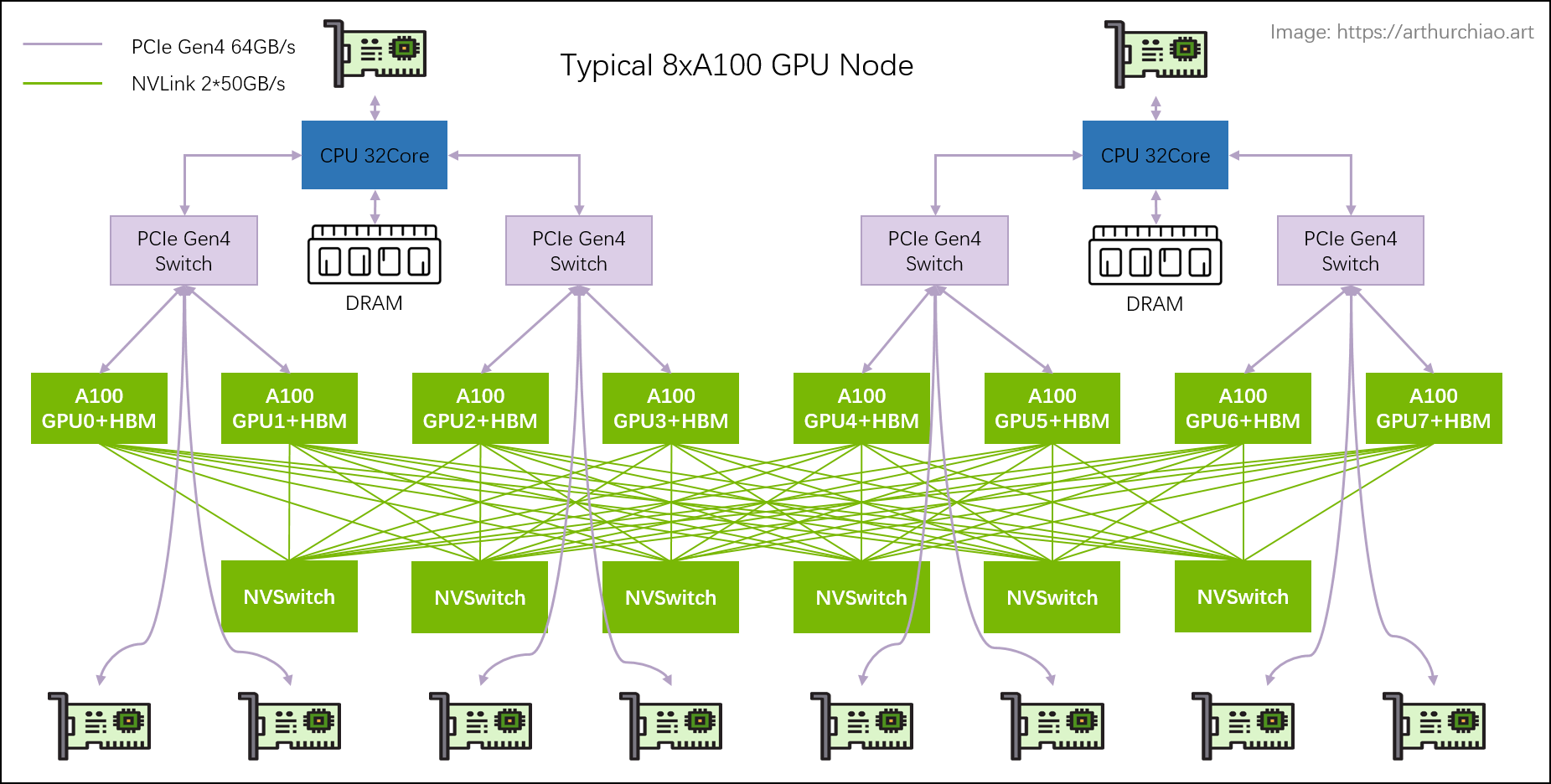
下面这图是典型 8 张英伟达的A100 卡组成的全网状拓扑, 使用了NVLink的双向带宽可达600GB/s。
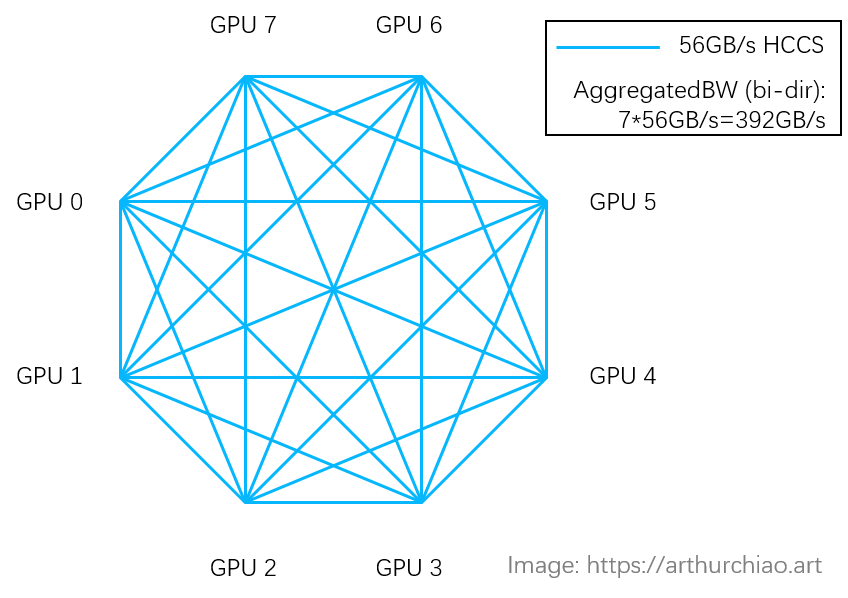
下面这图是采用了8张昇腾 910B GPU 卡组成的对等拓扑,互连带宽是392GB/s。
最新A100/A800/H100/H800/910B/H2004 的互连带宽对比:
| A800 (PCIe/SXM) | A100 (PCIe/SXM) | Huawei Ascend 910B | H800 (PCIe/SXM) | H100 (PCIe/SXM) | H200 (PCIe/SXM) | |
|---|---|---|---|---|---|---|
| Year | 2022 | 2020 | 2023 | 2022 | 2022 | 2024 |
| Manufacturing | 7nm | 7nm | 7+nm | 4nm | 4nm | 4nm |
| Max Power | 300/400 W | 300/400 W | 400 W | 350/700 W | 700W | |
| GPU Mem | 80G HBM2e | 80G HBM2e | 64G HBM2e | 80G HBM3 | 80G HBM3 | 141GB HBM3e |
| GPU Mem BW | 1935/2039 GB/s | 2/3.35 TB/s | 4.8 TB/s | |||
| GPU Interconnect (one-to-one max bw) | NVLINK 400GB/s | PCIe Gen4 64GB/s, NVLINK 600GB/s | HCCS 56GB/s | NVLINK 400GB/s | PCIe Gen5 128GB/s, NVLINK 900GB/s | PCIe Gen5 128GB/s, NVLINK 900 GB/s |
| GPU Interconnect (one-to-many total bw) | NVLINK 400GB/s | PCIe Gen4 64GB/s, NVLINK 600GB/s | HCCS 392GB/s | NVLINK 400GB/s | PCIe Gen5 128GB/s, NVLINK 900GB/s | PCIe Gen5 128GB/s, NVLINK 900 GB/s |
可以看到,对比英伟达的H100,华为的昇腾在互连带宽上的差距就越来越明显。引用知乎5 【红星路活跃的仙茅】的评论做一下总结:
看到的只是一个主机节点内的速率,主机与主机之间的网络速率远小于节点内的,这是个瓶颈,这卡住了,整个集群就快不了,主机之间的速率两者都差不多,差在软件配套上罢了!
瓶颈在主机之间速率,毕竟都要多个主机建立集群的,而不是单个!华为的和英伟达的在那个方面都差不多,落后在于软件配套上面!





